日志0002
一、流水账
因为最近都忙,没有及时记录,故将这几日内容一并记录
学习内容
阅读内容:
1、《艺术的故事》13-15章
生活内容:
锻炼内容:
1、篮球+跑步(因为记不住了就只记录今天的)
- 篮球2h
- 跑步三公里
发生的事:
这几天就大多数时间都是自习,周三上午上课,下午晚上去看了大创,然后部署chatglm,周四成功部署,此外精细化了一下我之前的画。
二、计划和达成
<b>大创记录</b>
前面的日子是自己摸索,尝试了CVS文件处理,kmeans算法,这周三4/12拿到了学长的代码,现在开始尝试阅读和学习。
4/13(补记录)
代码是用的jupyter notebook写的,尝试了在自己电脑上配置对应环境,失败,主力跑代码要用有两个显卡的服务器。
任务
1、阅读代码理解代码
2、将代码改写成GPU调用
做了什么
1、尝试了在自己电脑上配置对应环境(失败)
2、尝试改代码(时间不够,明日尝试)
4/14
未完成
1、阅读代码理解代码
2、将代码改写成GPU调用
新任务
无
做了什么
1、把环境配置好了,可以跑通代码了
2、把路径改为相对路径
三、随笔
1、读艺术的故事让自己对绘画有了新的理解,从意识到文艺复兴时透视法才被艺术家们征服后我知道了,艺术为什么说画的像并不重要了。然后就是,西方建筑和雕塑也开始震撼我了,人类的智慧呀。特别是希腊的雕塑,很难想像中世纪切断艺术的时代之前会有如此伟大的作品。
2、自从认识到自己的定义后,人生通透了许多,对了还有一个有意思的经历,是梳理自己的前几天遇见的一位应用心理学研究员,她和我说,读哲学而不读心理学,哲学会让人通透,心理学会让人钻牛角尖。
ChatGLM搭建记录
ChatGLM
一、基本流程
0、学习初衷
1、ChatGLM简介
github地址:https://github.com/THUDM/ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。
2、流程
2.0 基础
- 安装好了git,能访问GitHub。(会使用基本git命令行)
- 安装好了anaconda。(会基本的pip、conda命令行)
如果你的电脑完全没有配置过python环境,你需要先学会如何安装Anaconda等来配置python环境,这里因为我以前已经安装过,所以直接从搭建PyTorch环境开始。
- 合适的显卡驱动版本
显卡驱动,我以前玩游戏更新过,按理说有显卡的电脑都会有,可以更新一下。
2·1 搭建PyTorch环境
<b>官方文档是默认你配置好环境了的。</b>
我是先看官方文档把文件clone后,跑代码时报错
<pre>Torch not compiled with CUDA enabled</pre>搜索知道,没安装环境
2·1·1 安装CUDA
- 这里CUDA的版本建议先去PyTorch官网(https://pytorch.org/get-started/locally/)上查看。
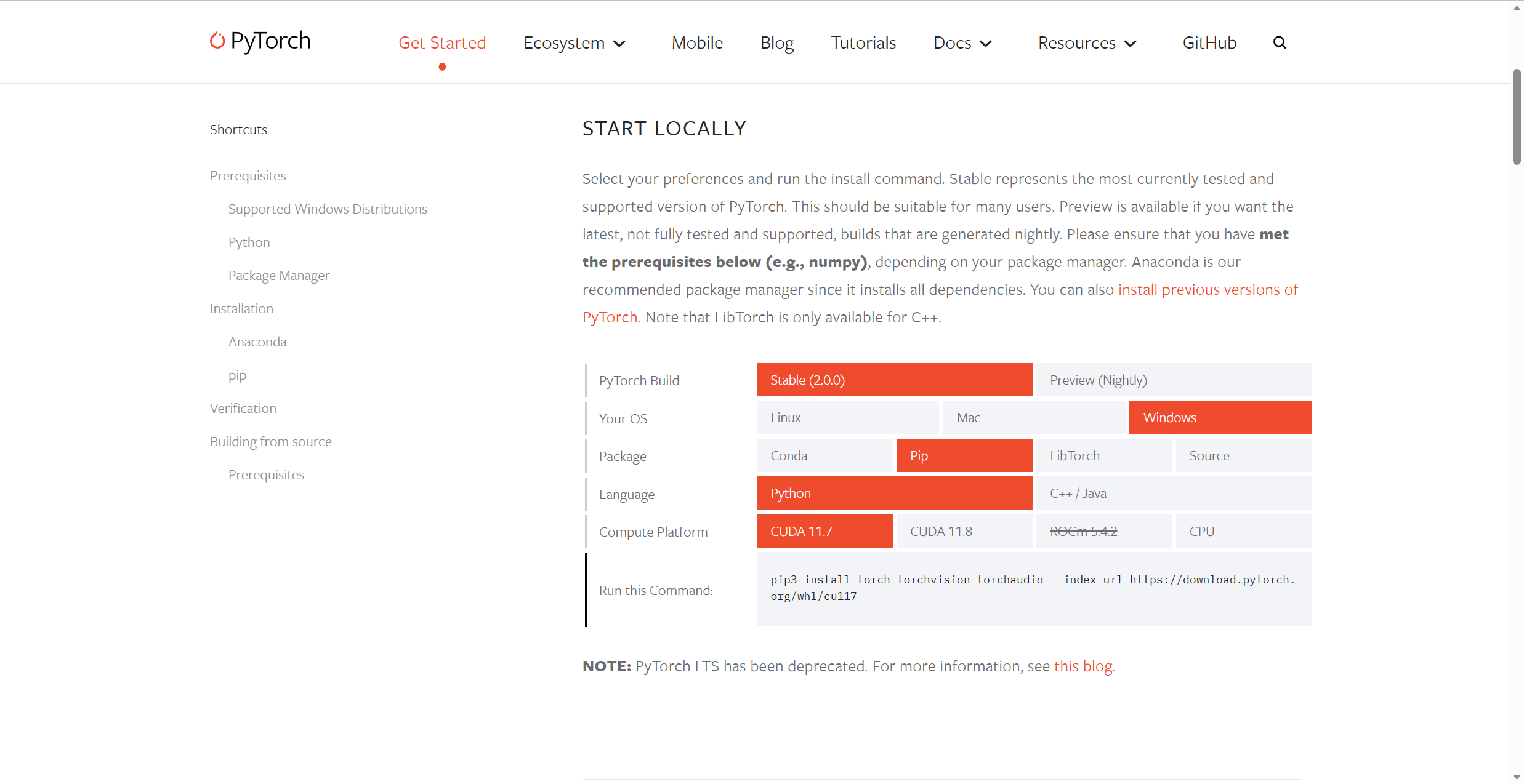
这里找到PyTorch有CUDA11.8版本,所以建议下载11.8版本(CUDA按理说是向下兼容的,但直接下对应版本会更保险一点吧)。
CUDA安装时如果已经安装了高版本,想降版本时,可以直接下载低版本的CUDA,按流程走一次就行。
去到CUDA官网下载对应版本CUDA https://developer.nvidia.com/cuda-toolkit-archive
下载后是一个安装程序(安装步骤可以看参考安装办法下载2<>)
2.1.2 安装CuDNN
- CuDNN下载后是一个一个压缩包,使用步骤看参考安装办法下载2
<pre>
2.1.3 用conda创建新的环境安装对应环境
这里注意python的版本选择
- 使用anaconda prompt创建环境。(之前用vscode的终端键入指令,不太好使)
- 创建新环境
<pre>conda create -n 环境名字(按喜好,用英文) python=版本号</pre> - 激活 conda activate 环境名字
2.1.4 最后安装PyTorch
pytorch选择对应版本的指令然后键入激活环境后的anaconda prompt中,等待下载(如果慢,可以找找换源,或者尝试参考网站1的办法)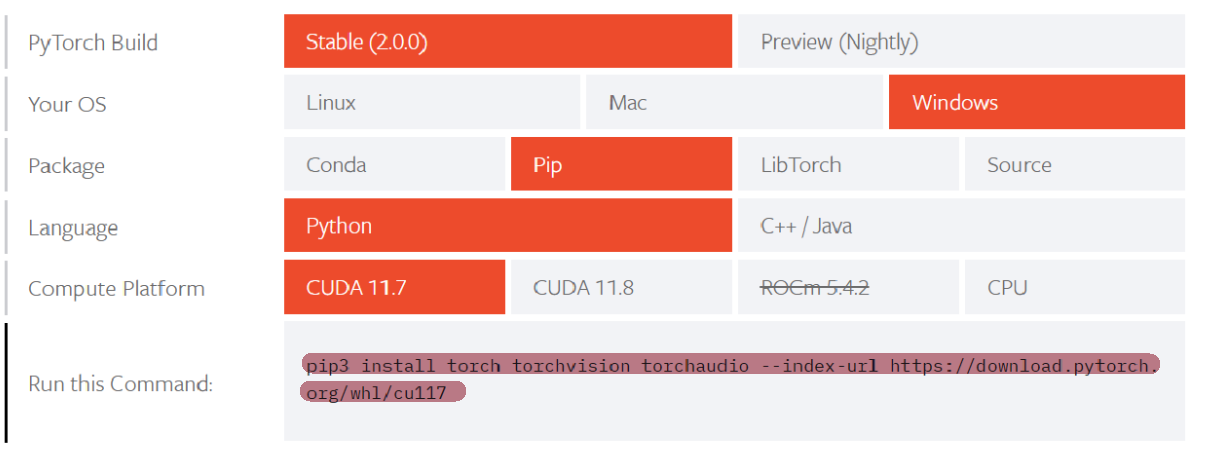
安装完成后
运行py脚本测试安装结果
import torch
print(torch.__version__)
print("是否可用:", torch.cuda.is_available()) # 查看GPU是否可用
如果是否可用返回true,则安装成功。如果返回false,可能是安装成了cpu版本的Pytorch(我就是)。可以卸载Pytorch后重新安装(可以看参考网站3)
2.1.5 参考网站(驱动问题可以看这个)
- 防坑指南-pytorch-GPU下载安装 https://zhuanlan.zhihu.com/p/454839461
- Cuda和cuDNN安装教程(超级详细)https://blog.csdn.net/jhsignal/article/details/111401628
- pytorch安装及卸载https://blog.csdn.net/mao_hui_fei/article/details/112078113
2·2 安装 ChatGLM
如果安装好pytorch环境之后跟着官网的流程来就行,是中文的,对中国人非常友好
全程都下载在新环境里面。
- 下载代码
git clone到文件夹
git clone https://github.com/THUDM/ChatGLM-6B.git
运行结束后,在终端切换到对应文件夹里面
- 安装Gridio
# 安装gradio用于启动图形化web界面 pip install gradio
- 安装依赖(会自动下载ChatGLM-6B文件里面requirements.txt里的依赖,注意要切换到ChatGLM文件里面)
# 安装运行依赖 pip install -r requirements.txt
- 运行效果
我使用的时vscode编译pythonvs code切换环境按shift+ctrl+p,点击pyton解释器,选择之前创建的环境(切换到对应的环境才能使用环境里面下载的包)
直接运行web_demo.py等待一段时间后就可以使用了
科学上网时无法运行
- GPU运行、CPU运行
可能会遇见显存不够的报错。这里可以切换model更改代码的
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
GPU
# FP16精度加载,需要13G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
# int8精度加载,需要10G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(8).cuda()
# int4精度加载,需要6G显存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
CPU
#32G内存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).float()
#16G内存
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).bfloat16()
- 结果
打开生成的网址就可以开始问问题了。
二、难点
1、显卡驱动的更新、CUDA、CuDNN版本的选择
2、<b>下载GPU版本的PyTorch</b>(使用GPU跑代码时需要)
3、网络问题
三、拓展知识
1、GLM模型
2、PyTorch是什么
3、CUDA、CuDNN是什么
4、Gridio是什么
5、ChatGLM的更多了解
四、疑惑
日后将进一步阅读代码
1、运行chatglm后会在用户目录下出现一个大的缓存文件.cache里面有一个叫 huggingface的文件,会特别占用C盘内存。
测试后是,每回答一个问题就会消耗内存。
日志升级01
今日决定对blog内容升级,并且借此机会把我的计划重构,让未来可以有条理,而不至于让自己莫名其妙的处理突发事件。
blog内容
首先写下我建立blog的本意,1、是为了能为人生框定一个比较固定的框架能够保证我在不断挑战和突破中保留一片净土,2、是为了能够方便读懂自己,能在未来可能的三观变动的日子不断让心中之树成长,而且减去枝丫,解决问题。3、是为了留下点什么,这也是当初写日记的初衷。
希望它可以变成一艘船,可以渡己亦渡人,最后刻上我的名字变成一艘永生的墓碑。
1、内容写作:
这里我会开始使用一些模板,并且长期实验它们,以求达到一个可以合服我自己的省时,有用的模板。
日志类:
这一项可能大多会写在日记本上,以求避免自己“虚伪”,可我大概已经虚伪了十几年了,说不定已经内化了呢?
这是一个参考的模板
影响情绪的:记录好起因经过结果。(记录问题,找办法)
做了什么:随性,想到就写学习也是写入其中(记录流水账,方便复盘)
思考了什么:等于以前的随笔吧(就改成随笔类吧)
- 观察到什么
- 感悟到什么
- 与自己对话
(加上计划)
读书、学习笔记类:
这是要单独立项的笔记类
重点——疑惑——拓展——总结
markdown语法学习
4-10:
任务列表
- 任务一 未做任务
- + 空格 + [ ] - 任务二 已做任务
- + 空格 + [x]
diff语法
作用:在markdown文档中显示代码之间的差异
看编译器是否支持
Markdown代码框diff,高亮显示差异、增量、修改
1 | # 下面是案例 |
求知的孩子
对爱的感悟让恋爱不再充满神秘感,对人生意义的回答让他开始发现自己的本质。————题记
我以往曾认真明确的追寻过几样事物,“如何被爱和去爱”、“人生的意义”、“自我的定义”。它们一直被我认为是人生的大BOSS,准备用一生去寻觅和回答。
为了寻找爱的答案,我有过很多愚蠢的尝试,从上网一遇见谈论到自己对象的有“爱”人士就问“你们有什么爱情故事吗?”到后来鼓起勇气加了有好感的女孩却说着莫名其妙的话。
而对于人生意义的问题是在高三的时候问出来的,睡眠不足让自己进入一种空灵的状态,我开始第一次意识哲学。
自我的定义就得在最近以前了,大学的高密度社交生活让自己意识到过往的自己总是在模仿,总是在奉行“知其善者而从之”,却不是真正的自己。
随着经历和阅读,它们都有了答案。
《亲密关系》回答了爱,并告诉我更多解释写在心理学里;《哲学家都干了什么》回答了人生的意义,它说没意义又有意义;自己的经历回答了自己的定义,它说你翻翻过去的日记,答案就在过去。
于是我开始认识到了自己或者也是无数千千万万人的可能性,我也知道了我的答案。
它是从小到大我最大的欲望 <b>求知欲 </b>
心理学说,兴趣是婴儿产生的第一种情绪,好奇便是人学会的第一件事。有人说好奇心会在成年后死去,庆幸我还是孩子。
(第一篇认真的随笔,还可以补充,以后补充)
Linux的学习
- 技术
作业
输入三个数然后排序
使用的是三个if..else模拟冒泡排序法
#!/bin/bash
# read -p "PROMPT MWSSAGE"VARIABLE:PROMPT MWSSAGE是提示用户的信息
read -p "输入:" a1 a2 a3
# 模拟冒泡循环
# 排序if[condition-is-true]
if [ $a1 -gt $a2 ]; then
# -gt是大于的意思
temp=$a1
a1=$a2
a2=$temp
fi
if [ $a2 -gt $a3 ]; then
tamp=$a2
a2=$a3
a3=$temp
fi
if [ $a1 -gt $a2 ]; then
temp=$a1
a1=$a2
a2=$temp
fi
echo "升序:$a1 $a2 $a3"
echo "降序:$a3 $a2 $a1"
100以内奇数偶数分类
#!/bin/bash
echo "奇数 偶数"
sum=0
for i in {1..100}
do
if [ $((i%2)) -eq 0 ]
then
echo " $i"
else
echo -e "$i \c "
if [ $i -le 10 ]
then
sum=$((sum+i))
fi
fi
done
echo "前10行数字的和为: $sum"
awk版
awk学习
问答区
一、vim命令的个别按键的区别
1.i命令用于在光标所在位置插入文本。(常用)
2.c命令用于删除一段文本并进入插入模式(是修改文本)